A Data Warehouse Evaluation Model
Marc Demarest
marc@noumenal.com
April 1995

|
Publication History A version of this paper appeared in OReview.Com (when it was still known as the Oracle Technical Journal) in October 1995 (v1 n1 p29). The focus of the paper is on the proper methods for evaluating data warehousing technologies and architectures. The Oracle 7 information, now outdated, is provided strictly as a case study. |
After close to five years of doing DSS missionary selling, I have recently had the sense that the open systems data warehousing market is reaching critical mass.
Most of the major open database management system (DBMS) companies have announced or shipped new product focused on decision support systems (DSS) usage models, the multidimensional database community is vociferously touting online analytical processing (OLAP) as the next major step in database design, and the DSS client tool marketplace is more crowded than ever. In public forums, I no longer have to beat back angry hordes of DBAs after whispering the word "denormalization" in response to questions about DSS schema design, and the first database design tools conversant with multidimensional schema (MDS) design principles are appearing in the marketplace. Something seems to be happening.
Recently, to test this sense, I did some free-text-retrieval surfing in a large database of computer industry trade periodicals. The database in question included abstracts or the complete text of nearly 74,000 articles, published in about 100 of the industry's top trade periodicals for the year beginning in June of 1994 and ending in May of 1995. I was looking, in a global way, for occurrences of what are fast becoming classic open systems DSS buzzwords: data warehouse, data marts, DSS, decision support, multidimensional, OLAP and the like. The results are summarized in the table below.
Term Articles Average/Month
containing the
term
data warehouse 251 21
data warehousing 244 20
decision support 797 66
DSS 148 12
OLAP 84 7
multidimensional 284 24
A similar search I made a year ago, turned up on average about 40% the number of articles this search uncovered, These results seem to confirm what anyone who reads the trade press carefully recognizes: that something important is building in the DSS marketplace. And that is cause for both celebration and concern.
A History Lesson
Celebration because open systems DSS is both critical to commercial firms' business success and because so much of the really interesting and practical client/server technologies on the market today are connected in one way or another with DSS.
And concern, indeed, because we aren't yet ready for a full-blown trade in DSS. One of the first things that happens to an open systems marketplace when it reaches critical mass is that the terms developed in the earlier phases of the marketplace are evacuated, by the vendor community, of nearly all their meaning. The terms become vacuous, a market indicating a vendor's positioning of its product set, but little more than that.
What has already happened to the terms open systems, object-oriented and client/server is in danger of happening to the term data warehouse. So it seems appropriate to begin our investigation of evaluation criteria for data warehousing with a look back to where, in some very real senses, this market began: to Bill Inmon's Building The Data Warehouse.
In this now-classic work, Inmon defines what he means by data warehouse fairly crisply.
A data warehouse is a subject-oriented, integrated, nonvolatile, time-variant collection of data in support of management's decisions.
The definition is crisp, but not without points requiring significant interpretation, and generating significant controversy.
Take the term subject-oriented for example. In Building The Data Warehouse, Inmon's examples of subjects -- customers, products, policies, and the like -- are pretty clearly what the multidimensional community has taught us to call dimensions: the avenues end-users employ to get to the facts of the business. One of those dimensions --for many firms, the key dimension -- is time, which Inmon calls out separately. Yet, in market practice, the term subject-oriented has come to mean, quite often, functionally-aligned: sales data is separated from marketing data is separated from manufacturing data, and each is ensconced in a separate "data warehouse," in effect recapitulating the functionally-aligned models of OLTP system design that got us into trouble in the first place.
Or consider the term integrated. Inmon's notions of integration revolve around the problem of inconsistent data types, entities and attributes. The data warehouse serves to undo the inconsistencies among production applications. As early adopters have put the data warehousing model to work, they have discovered other, equally beneficial kinds of integration provided by the data warehousing model, particularly the data warehouse's ability -- when deployed within a proper architecture -- to protect the production applications feeding the warehouse from extract drain: demands, during off-peak times, for large extracts from production data sources. In an environment with no data warehouse -- where, for example, a dozen or more data marts, each with its own extract requirements, have been deployed -- the extract windows of production systems are quickly exhausted. There are simply not enough hours in the day to feed the data marts. Increasingly, integrated is coming to mean central, mediating and protecting as well as consistent.
Finally, consider the idea that a data warehouse serves management. In the relatively brief period of time since Building The Data Warehouse was written, we have witnessed a revolution in managerial theory and organizational design, and its effect on decision support systems architectures has been to replace the term management with the term knowledge worker, as decision points are pushed down the organizational hierarchy, out to the boundaries of the firm, where knowledge workers care for customers, manage suppliers, and plot product line and market strategies.
Taken in its entirety, Inmon's definition holds. And it's a definition we need to hold closely as we begin to examine how we might evaluate alternative data warehouse technologies.
A Model For Evaluating Data Warehousing Technology
I have argued elsewhere (Building The Data Mart, in DBMS Magazine, July 1994) that, given the complexity of enterprise decision support systems architectures, it is appropriate to think of the data warehouse as:
- the upper tier in a two-tiered DSS architecture
- functionally analogous to the logistics center or warehouse
in an over-the-road logistics model, concerned more with consolidation
and shipment than with the retailing of data to end-user communities
- quite possibly a single, unitary logical data repositories for the firm, serving multiple data marts that recast data sets for specific discrete user communities.
This architectural model, I have suggested, allows DSS designers to deal separately with two vexing classes of database design problems:
- the design-for-integration model called out by Inmon's definition:
the notion that, in DSS environments, standard, uniform data elements
and models must prevail to rationalize the competing models of
production systems.
- the design-for-legibility issue: the idea that, to employ the increasingly inexpensive and well-integrated desktop tools produced by DSS client tool vendors, DSS database schema must be immediately and intuitively navigable by end-users with no technical knowledge of database design, joins, primary and foreign keys, and the like.
Such a hybrid model would look something like this:
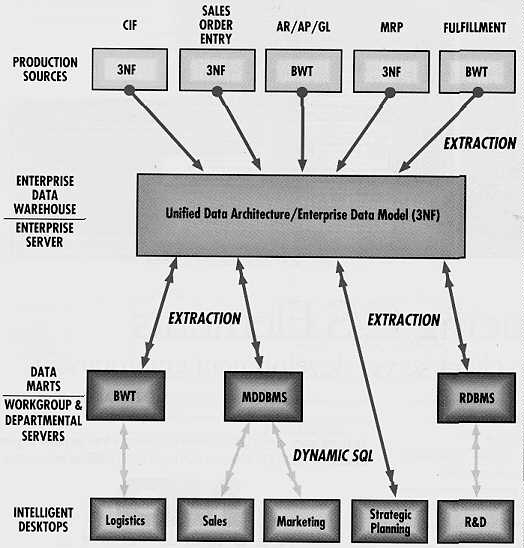
Figure 1 -- Demarest's Hybrid Warehousing/Marting Model
In this kind of environment, I would argue that data warehouse technologies need to be evaluated in five critical areas:
- capacity: what are the outer bounds of the DBMS technology's physical storage capability, and what in practice (meaning in real-world, referenceable commercial applications) are the boundaries of the technology's capacity?
- loading and indexing performance: how fast does the DBMS load and index the raw data sets from the production systems or from reengineering tools?
- operational integrity, reliability and manageability: how well does the technology perform from an operational perspective? how stable is it in near-24x7 environments? how difficult is it to archive the data warehouse data set, in whole or in part, while the data warehouse is online? what kinds of tools and procedures exist for examining warehouse use and tuning the DBMS and its platform accordingly?
- client/server connectivity: how much support, and what kinds of support, does the open market provide for the DBMS vendor's proprietary interfaces, middleware and SQL dialects?
- query processing performance: how well does the DBMS' query planner handle ad hoc SQL queries? How well does the DBMS perform on table scans? on more or less constrained queries? on complex multi-way join operations?
None of these areas is exclusively the province of the DBMS technology; all depend on the elusive combination of the right design, the right DBMS technology, the right hardware platform, the right operational procedures, the right network architecture and implementation and the hundred other variables that make up a complex client/server environment. Nevertheless, it should be possible to get qualitative if not quantitative information from a prospective data warehouse DBMS vendor in each of these areas.
Capacity
Capacity is a funny kind of issue in large-scale decision support environments. Until just a few years ago, very large database (VLDB) boundaries hovered around the 10 gigabyte (GB) line, yet data warehouses are often spoken of in terms of multiple terabytes (TB).
DSS is generally an area where, prior to the first DSS project, data machismo reigns: the firm with the biggest warehouse wins, and sometimes I get a feeling that the design principle at work is "let's put everything we have into the warehouse, since we can't tell quite what people want."
The reality, in my experience, is that:
- well-designed warehouses are typically greater than 250 GB for a mid-sized to large firm. The primary determinants of size are granularity or detail, and the number of years of history kept online.
- the initial sizing estimates of the warehouse are always grossly inaccurate.
- the difference between the raw data set size (the total amount of data extracted from production sources for loading into the warehouse) and the loaded data set size varies widely, with loaded sets typically taking 2.5 to 3 times the space of raw data sets.
- the gating factor is never, as old guard technologists seem to think, the available physical storage media, but instead the ability of the DBMS technology to manage the loaded set comfortably.
- any DBMS technology's capacity is only as good as its leading-edge customers say (and demonstrate) that it is; a theoretical limit of a multiple terabytes means little in the face of an installed base with no sites larger than 50 GB.
Loading And Indexing Speed
Data engineering -- the extraction, transformation, loading and indexing of DSS data -- is a black art, and there are as many data engineering strategies as there are data warehouses. My firm has customers using state-of-the-art reengineering and warehouse management tools like those from Prism and ETI, customers using sophisticated home-grown message-based near-real-time replication mechanisms, and customers who cut 3480 tapes using mainframe report writers. The bottom line is that the specifics of a DBMS technology's load and indexing performance is conditioned by the data engineering procedures in use, and it's therefore necessary to have a clear idea of likely data engineering scenarios before it is possible to evaluate fully a DBMS' suitability for data warehousing applications.
This area of evaluation is made more complex by the fact that some proprietary MDDBMS environments lack the ACID characteristics required to recover from a failure during loading, or do not support incremental updates at all, making full drop-and-reload operations a necessity.
Nevertheless, it is definitely my experience that significant numbers of first-time DSS projects fail not because the DBMS is incapable of processing queries in a timely fashion, but because the database cannot be loaded in the allotted time window. Loads requiring days are not unheard of when this area of evaluation is neglected, and, when the warehouse is refreshed daily, this kind of impedance mismatch spells death for the DSS project.
Operational Integrity, Reliability and Manageability
A naive view of DSS would suggest that, since the data warehouse is a copy of operational data, traditional operational concerns about overall system reliability, availability and maintainability do not apply to data warehousing environments. Nothing could be farther from the truth.
First of all, the data warehouse is a unique, and quite possibly the most clean and complete, data source in the enterprise. The consolidation and integration that occur during the data engineering process create unique data elements, and scrub and rationalize data elements found elsewhere in the enterprise's data stores.
Second of all, the better the enterprise DSS design, the more demand placed on the warehouse and its marts. Effective DSS environments quickly create high levels of dependency, within end-user communities, on the warehouse and its marts; organizational processes are built around the DSS infrastructure; other applications depend on the warehouse or one of its marts for source data. The loss of warehouse or mart service can quite literally bring parts of the firm to a grinding, angry halt.
Bottom line: all the operational evaluation criteria we would apply without thinking to an online transaction processing (OLTP) system apply equally to the data warehouse.
Client/Server Connectivity
The warehouse serves, as a rule, data marts and not end-user communities. There are exceptions to this rule: some kinds of user communities, particularly those who bathe regularly in seas of quantitative data, will source their analytic data directly from the warehouse.
For that reason, and because the open middleware marketplace is now producing open data movement technology that promises to link heterogeneous DBMSs with high-speed data transfer facilities, it is important to understand what kind and what quantity of support exist in the open marketplace for the DBMS vendors proprietary client/server interfaces and SQL dialects. A DBMS engine that processes queries well, but which has such small market share that it is ignored by the independent software vendor community, or supported only through an open specification like Microsoft's Open Database Connectivity (ODBC) specification, is a dangerous architectural choice.
Query Processing Performance
Query processing performance, like capacity, is an area of the DSS marketplace in which marketing claims abound and little in the way of common models or metrics are to be found.
Part of the practical difficulty in establishing conventions in this area has to do with the usage model for the warehouse.
If, for example, the warehouse is primarily concerned with populating marts, its query performance is a secondary issue, since it is unlikely that a large mart would request its load set using dynamic SQL, and far more likely that some kind of bulk data transfer mechanism, fed by a batch extract from the warehouse, would be used.
If the warehouse serves intensive analytic applications like statistical analysis tools or neural network-based analytic engines, or if the warehouse is the target for (typically batch-oriented) operational reporting processes, the warehouse is likely to have to contend with significant volumes of inbound queries imposing table scanning disciplines on the database: few joins, significant post-processing, and very large result sets.
If, on the other than, the warehouse is connected directly to significant numbers of intelligent desktops equipped with ad hoc query tools, the warehouse will have to contend with a wide range of unpredictable constrained and unconstrained queries, many of which are likely to impose a multi-way join discipline on the DBMS.
All of these usage models suggest different performance requirements, and different (and perhaps mutually exclusive) database indexing strategies. Thus -- as is the case with load and indexing performance -- its is critical to have a clear idea of the warehouse usage model before structuring performance requirements in this area.
Under Test: Oracle 7.1 PQO
The Test Case
To test large-scale DSS technologies, Sequent's DecisionPoint™ decision support systems practice uses a reference database developed expressly for that purpose. The database consists of five large tables, loaded with Wisconsin Benchmark style data, as described in the table below. We structured this database in a classic data cube or star schema, and based both the schema and the data volumes on our experience with over 50 large-scale commercial DSS implementations.
Table Number Of Row Width (average Number Of Table Size
Rows bytes) Columns
T200M 200,000,000 248 bytes 24 46.2 GB
T50M 50,000,000 248 bytes 24 11.6 GB
T25M 25,000,000 509 bytes 48 11.9 GB
T10M 10,000,000 509 bytes 48 4.7 GB
T5M 5,000,000 247 bytes 24 1.15 GB
The system under test in this case is Oracle's V7.1 database management system, with the Parallel Query Option (PQO) technology introduced in 1994. We ran 7.1 on a Sequent Symmetry SE60, configured as indicated in the table below.
CPUs 16 66MHz Pentium processors
Memory 1.5 GB
Disk subsystem 18 fast wide differential SCSI-2 I/O
channels, supporting 180 1 GB drives
The database was allocated and spread across the SE60's disk array as indicated in the table below
T200M 50 disks T50M 25 disks T25M 25 disks T10M 25 disks T5M 25 disks
The loaded size of the database with indices was 109.4 GB.
Capacity
Oracle V7.1 handled the test database with ease. This came as no surprise to us, since Sequent customers have run production DSS environments with as much as .75 TB of online data under Oracle's control, and Oracle-based DSS environments of 200 GB and greater are increasingly common.
Loading And Indexing Speed
Thanks to the well-mated parallel capabilities of Oracle V7.1 and the Symmetry platform, loading and indexing performance was generally excellent in the test environment.
Parallel database load times consistently averaged 10 GB per hour across the test suite.
A CREATE INDEX operation on T25M (the 25 million row table) that built a 378 MB index took 12.5 minutes in parallel; the equivalent operation, in single stream mode, took 2.94 hours (more than 176 minutes), making the parallel operation roughly 15 times faster than the single stream case.
Operational Integrity, Reliability and Manageability
Oracle V7.1's native management and instrumentation tool set is more robust than any previous version of the product. Combined with the increasingly large and sophisticated array of third-party management and monitoring tools, as well as clustering technology like that available for the Symmetry 5000 family, Oracle V7.1 allows savvy DSS designers and implementers to build a highly-available warehouse environment that can be monitored and tuned effectively, and under most conditions backed up online.
Client/Server Connectivity
Oracle's client/server connectivity is unparalleled, and the number of client tools and middleware products supporting Oracle's SQL dialect and the SQL*Net APIs continues to grow. Most enterprise-grade independent software vendors (ISVs) working in the DSS marketplace that I am personally familiar with target Oracle as either their first or second DBMS; only Sybase's OpenClient/OpenServer API has an equivalent level of support.
Query Processing Performance
In the test environment, Oracle's query processing faired well. A full scan of the 46.2 GB in the T200M table (200 million rows) took only 18.3 minutes in parallel, compared with a single stream response time of 5.13 hours (about 307 minutes): the parallel case was nearly 17 times faster than the single stream case.
A query that imposed a full table scan, a GROUP_BY operation, a SORT and an on-the-fly aggregation on the same table (T200M) took 39.5 minutes in parallel, and 10.2 (612 minutes) hours in the single stream version.
Finally, A SORT/MERGE join of T5M (5 million rows/1.15 GB) and T50M (50 million rows/11.6 GB) completed in 37.75 minutes in parallel, and in 7.68 hours (about 460 minutes).
Conclusions
Oracle, along with Informix, is the top contender for large-scale commercial data warehouses, at least where open systems technology is concerned. Oracle, like Informix, has done significant work to make its technology scalable and highly-performant on scalable SMP platforms like the Symmetry 500 line, and all the firms deploying significant DSS projects with which I am familiar are using one technology or the other for what I would call data warehouses: large central DSS servers, supporting data marts of a wide variety, including open DBMS, proprietary multidimensional database management systems, and, in not a few cases, flat file LAN databases.
Oracle's 7.1 PQO technology performs well in medium-to-large data warehousing environments, and fairs very well inside the evaluation framework on all counts. In particular, its performance in symmetric multiprocessing environments (SMP) removes many of the traditional barriers to the use of conventional RDBMS technology in large-scale DSS environments.
In the final analysis, however, successful decision support environments are the product of capable technologies integrated and deployed within the framework of a carefully considered enterprise DSS architecture. DSS is not a project, or a series of project -- it's a way of thinking about the information dissemination infrastructure for the firm, a way of designing large-scale client/server environments, a way of life.
We would do well to go back, again, to Inmon's book, and reread the warning he left for us there.
One of the manifestations of the information processing profession's youth is the insistence on dwelling on detail. There is the notion that if we get the details right, the end result will somehow take care of itself and we will achieve success. It's like saying that if we know how to lay concrete, how to drill, and how to install nuts and bolts, we don't have to worry about the shape or the use of the bridge we are building. Such an attitude would drive a more mature civil engineer crazy.
Remembering Inmon's dictum that DSS environments are iterative and evolutionary, and thinking of enterprise-wide DSS as an entire urban roadway infrastructure -- the information arteries of the firm -- we begin to understand its complexity correctly.
Performance, as I've said in other contexts, is not a characteristic of architecture, but of implementations. Performance requirements and usage models are, however, characteristics of design, and Oracle 7.1 PQO technology, in the proper enterprise DSS architecture, is a clear front runner.
The author wishes to acknowledge the work done by Mark Sweiger, Mary Meredith, and other members of Sequent's DecisionPoint DSS practice group in preparing and running the tests on which this article is based.
Last updated on 06-22-97 by Marc Demarest (marc@noumenal.com)
The text and illustrations in this article are copyright (c) 1994 by OReview.COM and Marc Demarest.
The authoritative source of this document is http://www.noumenal.com/marc/oracle7.html